Webスクレイピングに興味を持ち、色々調べていたところSeleniumというライブラリが便利そうだったので試したメモです。
環境
私の環境は以下の通りです。
・OS:Win10
・Edgeのバージョン:100.0.1185.44
・Pythonのバージョン:3.7.4
・seleniumのバージョン:3系(当時の環境メモしわすれてました)
Selenium概要
Seleniumの公式ホームページを見ると、Seleniumは各種ブラウザに対応したWebドライバを用いてブラウザを操作するシステムみたいです。
コンポーネントとしては下記のような構成になっているそうです。
(下記図は一番シンプルな構成です。他にもリモート通信などあるみたいですが、詳細は下記図の引用元の記事を参考お願いします。)3
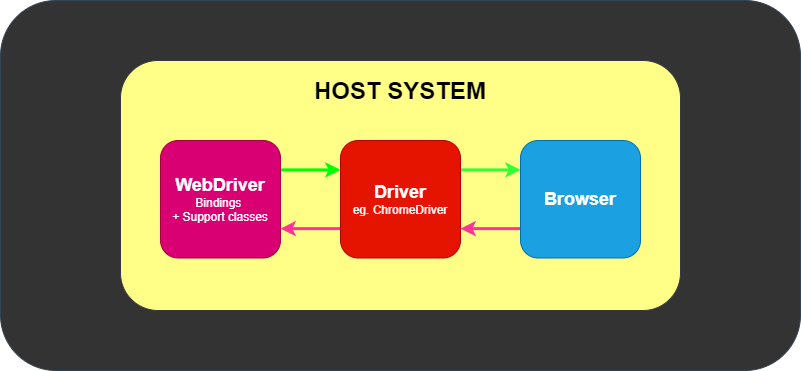 |
| https://www.selenium.dev/ja/documentation/overview/components/より引用 |
Seleniumの環境構築
先ほども少し説明しましたが、Seleniumを使ってWebスクレイピングをするためには
Selenium+Web ドライバが必要です。
まずはSeleniumをインストールします。
インストールは簡単でコマンドプロンプトでpipコマンドを実行します。
pip install selenium
次にEdge用のWebDriverをインストールします。
WebDriverはブラウザのバージョンによって異なるため、まず初めに自分のブラウザのバージョン確認です。
Edgeの場合は「設定」→「Microsoft Edgeについて」でバージョンの確認をすることが出来ます。私の場合は「100.0.1185.44」でした。

それでは早速seleliumのHello World的な指定したURLを開くという処理期日します。
ソースコードは下記のとおりです。
from selenium import webdriver
driver = webdriver.Edge(executable_path = 'C:\\...\\...\\msedgedriver.exe')#先ほどインストールしたドライバーが保存しているパス。フォルダパスの\を\\にすること
driver.get('https://twitter.com/')#指定したURLを開く注意点としてはフォルダパスを入力する際に\(バックスラッシュ)だけだとエスケープ文字として認識されてしまうので、\\であらわしてください。
今回はTwitterを開いたのですが、無事開くことが出来ました。また、Seleliumでブラウザを開くと「Microsoft Edgeは、自動テストソフトウェアによって制御されています。」という文言が表示されます。

フォームに入力する
seleniumの逆引きリファレンスがあったので、それを参考にフォームに文字を入力する処理を書きます。
まず最初にfind_element_by_xpathもしくはfind_element_by_nameというものを使ってテキストボックスの要素を取得します。
xpathの要素を取得するためにEdgeの適当なところで右クリックをして「開発者ツールで調査する」を押下します。

入力箇所の所のnameタグが"text"であることが分かりました。(Xpathを使って実施するパターンはうまくいきませんでした。。。)


これでユーザー名を入力できるようになりました。
import time from selenium
import webdriver
driver = webdriver.Edge(executable_path = 'C:\\Users\\kinao\\Downloads\\edgedriver_win64\\msedgedriver.exe')#先ほどインストールしたドライバーが保存しているパス。フォルダパスの\を\\にすること
driver.get('https://twitter.com/i/flow/login')#指定したURLを開く。今回はTwitterのログイン画面
time.sleep(2)#2秒待機
login_id = driver.find_element_by_name('text')#ログインのフォームの場所を探す
login_id.send_keys('ユーザー名')#ユーザー名をフォームに入力
今後の課題として調査です。。。
サイト上のボタンを押す/ボタンに表示されている文を取得
Twitterのログイン画面ではうまくいきませんでしたが、Yahooのページではうまくいったので紹介します。
今回はYahooを開いて下記URLをクリックしたいと思います。


import time
from selenium import webdriver
driver = webdriver.Edge(executable_path = 'C:\\Users\\kinao\\Downloads\\edgedriver_win64\\msedgedriver.exe')#先ほどインストールしたドライバーが保存しているパス。フォルダパスの\を\\にすること
driver.get('https://www.yahoo.co.jp/')#指定したURLを開く。今回はTwitterのログイン画面
time.sleep(2)#2秒待機
click_button = driver.find_element_by_xpath('//*[@id="TopLink"]/ul/li[2]/a/span/span')#xpathを使って要素を探す
print(click_button.text)#要素に記載されているtextを表示
click_button.click()Yahooの場合は問題なくボタンをクリックし、該当のページに遷移することが出来ました。
print文でボタンに表示されている「ヤフー限定特典 LINEMOの契約がオトク」という文字列も取得出来たので、動作としては問題なしですね。

やはりTwitterの画面が少し特殊なのかもしれません。。。下記サイトの内容が原因だと思い試した見たのですがそれでもうまくいきませんでした。。。今後の課題として調査です。。。
今回のコードの注意点(2024/01/21)
今回のコードはSeleniumのバージョンが3系の記述で記載されています。
最近時はSeleniumのバージョンがアップデートされ、4系が出ているのですが3系と4系で書き方に互換性が無く、今回のコード4系の環境で実行してしまうとエラーが出てしまい動きません。
最近時はSeleniumのバージョンがアップデートされ、4系が出ているのですが3系と4系で書き方に互換性が無く、今回のコード4系の環境で実行してしまうとエラーが出てしまい動きません。
バージョン4の変更点については下記サイトなどを参考にして下さい。
まとめ
今回はSeleniumを使ってEdgeでサイトを開いたり、フォームに入力したり、ページを遷移させたりさせることが出来ました。
Twitterのログイン画面など一部のサイトで想定通りの動作が出来なかったため、今後の宿題として調べていきます。。。










0 件のコメント:
コメントを投稿